开云kaiyun(中国) 视频AI卷向5分钟: 全量开源, 一次生成, 认真告别「盲盒抽卡」


编订|泽南、杨文
AI 视频生成,卡在长视频这谈坎上太深远。
2026世界杯赛事竞猜中国官网往日一年,视频生成赛谈动作频频。谷歌推出 Veo 系列,并在本年 I/O 大会发布新一代多模态视频生成与编订模子 Gemini Omni Flash;字节的 Seedance2.0、快手可灵、阿里的茂盛马也一次又一次,毁坏了咱们的预期。
各家模子生成的画面一个比一个颜面,只能惜时长大多不高出 20 秒。一朝把视频拉长到分钟级,空匮就来了,要么是吞并脚色跨镜头后焕然一新,要么是说着说着声息变了或没了;思改一个镜头,整条视频还得从头生成……
正因如斯,AI 长视频难以信得过过问专科内容出产的责任流。
最近,一项开源的新工夫却向咱们展示了一幅完全不同的图景。
先来看个 case。

注:本视频内容仅供学术计划与工夫测评目标使用,无用于任何营业用途。
皮克斯格调的 3D 质感规复得尽头到位,动画细节处理也不迟滞。
要道是,两分半钟里涵盖十余个镜头,近景对话、前景追赶、公路全景轮流出现,场景间过渡处理得很顺滑,且脚色形象能持久保执一致,音画也同步当然。这迷漫是一次性生成的。
这个视频,恰是出自京东近期开源的长音视频生成框架 JoyAI-Echo。
相较于市面上其他视频模子,JoyAI-Echo 有三大亮点。
它或者竣事长达五分钟的跨镜头「音视频双重一致」,保证脚色的面部特征媾和话音色不变。
同期告别了往日「改一个镜头要重跑整条视频」的盲盒式生成,咱们不错平直通过当然语言指挥 AI 进行局部修改,竣事非线性编订与局部重绘。
此外,它支援流式延迟敛迹下的两档及时超分,最高可平直输出 1472×2560 分辨率的高清视频与精细化音频,餍足专科级内容出产门槛。
面前,该模子的代码和权重文献均已公开,可免费下载使用。
GitHub:https://github.com/jd-opensource/JoyAI-Echo
容貌主页:https://echo-team-joy-future-academy-jd.github.io/Echo-LongVideo-Page/
视频创作,无用抽卡了?
JoyAI-Echo 还跑出了一大堆视频,个个高出两分钟,自带配音。

本视频内容仅供学术计划与工夫测评目标使用,无用于任何营业用途。
从视频中咱们不错看到, 模子精确规复了暗澹写实的哥谭氛围,蝙蝠侠从雨中屋顶的特写对话,到俯冲高出、巷战、摩托追赶和仓库宝石,场景频频切换,但脚色外形、服装和环境格调持久融合,莫得出现常见的格调漂移。
湿滑大地和动态隐隐末端的处理,增强了动作戏的实在张力,雨声、脚步声、引擎轰鸣与对话也各占其位。

这类 vlog 视频,难点在于实在感。
穿牛仔的年青男人出当今各式场景自拍,开场手执自拍杆的当然涟漪与行走程序匹配当然,动作通顺,后续画面加入不同出镜者也莫得穿帮。
151 秒的视频画面中,男人面部玄虚、发型、色调与服装纹理保执高度一致,车辆、行东谈主和室内胪列等环境元素在不同视角间也过渡当然。

前几段生成视频还靠场景和动作撑起视觉张力,开云体育(中国)官方网站而这段视频比的是雅致度。
画面中的东谈主物发丝、毛衣质感和环境光影都很实在当然,女生肢体姿态也通顺。
不外,在快速切镜时,布景细节偶有眇小不一致,但不影响全体不雅感。
这么的阐扬,还是把 AI 视频生成从 demo 和搞笑视频生成器推向了工业级出产器具的范围。
过往的视频生成工夫受限于严重的时空高下文渐忘和时弊蓄积,很难用到故事创作、数字东谈主助手或及时内容生成等本色场景中。而 JoyAI-Echo 展现出的跨镜头「音画双重一致性」,解释了 AI 还是具备在万古序、复杂多视角下处理长篇脚色开动型叙事的才调,让 AI 信得过有了讲好一个完整长故事的可能。
JoyAI-Echo 也重塑了创作家与 AI 之间的互助范式。由于能平直输出具备语义意旨和高准确率的台词对话,视频创作告别了「输入 Prompt、拼运谈抽卡」的被迫模式,在智能体和局部重绘机制的扶植下,视频生成演进成了东谈主天真态互助的非线性编订的范式。
创作家当今不需要再为某一个穿帮镜头而将整条长视频推倒重来,极大地裁汰了改稿资本,AI 或者无缝地镶嵌到影视前期预演和动态分镜的责任流中。
那么 JoyAI-Echo 是如何作念到的?
如何攻克长视频生成难题?
从工夫论说中咱们不错看出,JoyAI-Echo 在底层架构、数据清洗、多模态对皆及推理加快上有不少更动之处。
该框架通过两层互补的工夫矩阵,攻克了长视频生成中万古一致性、高渲染延迟和低交互灵活性的行业难题。
百万级「身份向心型」语料,从泉源不断变脸
往日,大模子拍视频容易翻车,很猛进程上是被喂进嘴里的数据给误导了。传统 AI 视频老师高度依赖优化单镜头质料的平铺式数据集,这就导致模子只学过短时刻内画面怎样画才颜面,但莫得和会过吞并个脚色在不同期空、不同光影和服装下的视觉连贯性。
为此,JoyAI-Echo 构建了一套全新的身份向心型视频语料库(Identity-Centric Video Corpus),该活水线从电影、电视剧和长网页视频中,精确提真金不怕火出了高出 100 万个私有的脚色身份原型,再经过全局原型与时空去重,开云体育多轴质料过滤与流跟踪,紧凑型音视频纠合标注,为模子生成内容的一致性提供了保障。
「槽位配对」驰念机制,给面部和声息上双保障
在模子架构上,JoyAI-Echo 覆没了平直的端到端生成,转而接收基于渐进演化驰念库(Evolving Memory Bank)的迭代分镜合成机制。其中枢工夫在于联想了「槽位配对(Slot-Paired)」音视频驰念交互机制。
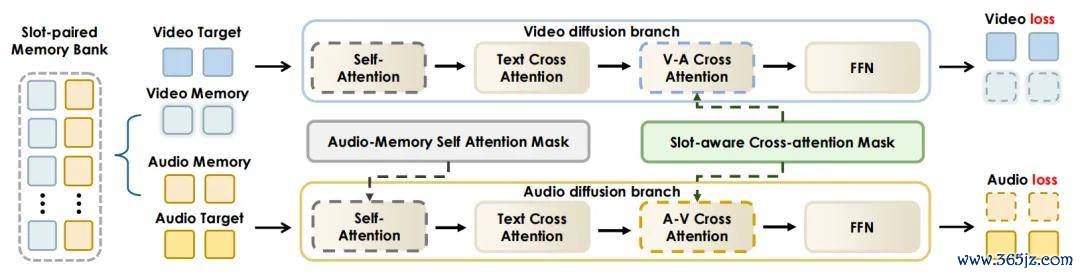
槽位配对视听驰念交互机制概览。
它尽头于给每个脚色的脸和声息进行了平直绑定。其中,每一个历史事件都包含对皆的视觉和音频驰念象征。在生成阶段,标的视频和音频象征由两个扩散分支进行处理,而驰念象征仅四肢条件高下文使用,不参与赔本策计。在音频分支中,「音频 - 驰念」自介怀力掩码抑制着标的音频象征与音频驰念象征之间特定层级的交互。
在跨模态模块中的「槽位感知」跨介怀力掩码,强制竣事了配对的视觉与音频驰念槽位之间的逐一双应交互,从而详确了跨事件的东谈主脸与声息稠浊。
由此,该模子在仅推断刻下视频和音频标的的同期,依然或者保执长程的视觉身份一致性及谈话东谈主音色的一致性。
后老师体系:嘴型对得准,推理快 7.5 倍
为使底层架构开释最大后劲,计划团队联想了一套由表及里的后老师体系。
长高下文赔本重定向与梯度放大(控口型):由于长高下文会让语音开动面部变得更繁难,在基础老师阶段,视频赔本权重会把柄刻下的驰念槽位长度进行动态调大,详确口型同步退化。同期,音频到视频的交叉模态梯度在 forward 不变的前提下被放大(二阶段放大至 6 倍),显耀强化台词对嘴型的抑制力。
多分辨率渐进式 SFT(提画质):将单镜头高清样本与概温存采样的多镜头语料交融 fine-tune。接收 480p 到 720p 渐进式分辨率改革,在增强单镜头与长视频画面质感的同期,完好意思剿袭了多镜头一致性才调。
OmniNFT 跨模态对皆强化(RLHF 对皆):针对多模态强化学习中「音画奖励不一致」、「视频梯度混浊浅层音频网罗」以及「对皆孝敬度分派不均」三大瓶颈,JoyAI-Echo 引入了 OmniNFT 框架。它竣事了模态特异性上风路由(镇静分发视觉、音频、同步奖励)、层级梯度手术(在浅层音频网罗断开视觉梯度,在深层保留交互),并哄骗视听交叉介怀力求谱四肢内在代理,对发声要道区域本质局部赔本重绘。
双向与因果 DMD 蒸馏(加快):为了透顶罢休生成设施冗长的硬件职守,团队接收分散匹配蒸馏(DMD)将多步双向生成器压缩为 8 步学生模子,且在老师时代均衡视听赔本统共,通过 EMA 优化器动量缓冲平滑音频 gradient 噪声。值得柔柔的是,DMD 老师中加入了驰念输入左迁模拟(Degradation),专诚模拟长序列滚出时自生成历史产生的漂移,使模子对谬误蓄积具备极强的鲁棒性。该架构还能当然蔓延至块状因果流式生成(Causal Streaming Generation),竣事从全高下文去噪到因果流式生成的无缝过渡。
在生成模子之上,JoyAI-Echo 又加入了两个让工业落地成为可能的模块。
智能导演智能体(Director Agent)传统的视频器具是「一次性输入、盲盒式抽卡」。而该智能体引入了「器具与手段抽象」责任空间,能把用户的隐隐需求自动细化为包含脚色卡、场景卡、分镜时长的结构化脚本。它哄骗 KOK(要道镜头的要道帧)政策提真金不怕火动态驰念条件。创作家淌若对某个镜头不自在,只需用大口语在评审阶段建议修改见识,智能体就会自动定位并针对该镜头进行局部重绘和驰念更新,整条长视频无需从头生成。
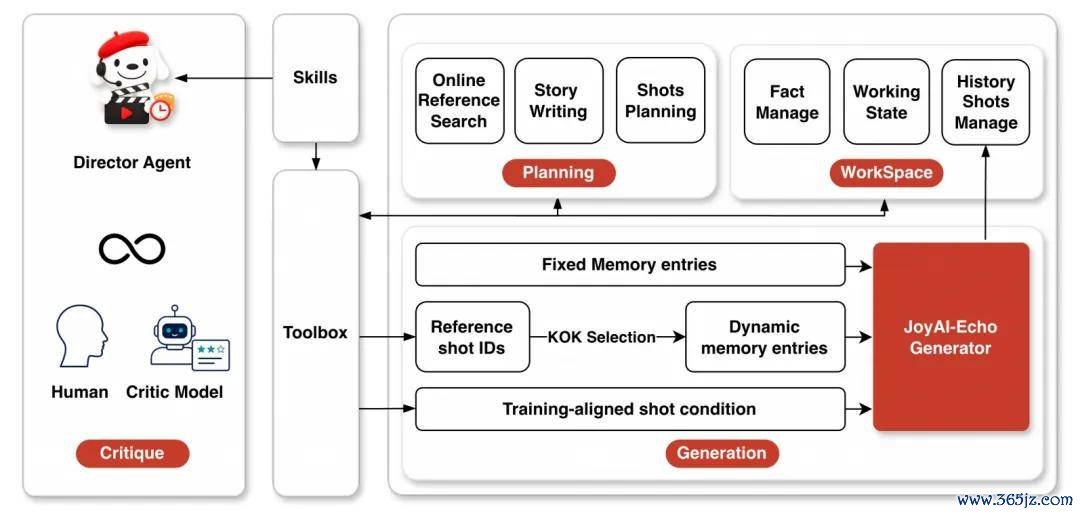
导演智能体(Director Agent)责任流概览。该智能体将长篇视频的生成过程分辩为探求、生成和评审三个阶段,支援哄骗局部响应进行非线性修改,再通过单步超分网罗进行高画质输出。
纠合单步超分架构(Unified One-Step SR)则将空间放大的算力职守从自纪念佛过中透顶解耦。依托超 87 万顶级视听语料,自研了 CondSRPatchifyProj 轻量级模块。它仅需单个扩散流前向设施,就能将 720p 潜在空间平直推广至 1152×1920(1K) 或 1472×2560(2K)的高清视听 Token 空间,在保管流式极低延迟的同期,大幅拉高了成片的细节好意思学。
通过在包含 100 个脚本故事、3000 个规章镜头(跨动漫、写实格调、含指定 IP 与原创脚色)的超永生成基准评测集上进行测试,JoyAI-Echo 的各项操办均位列前茅:
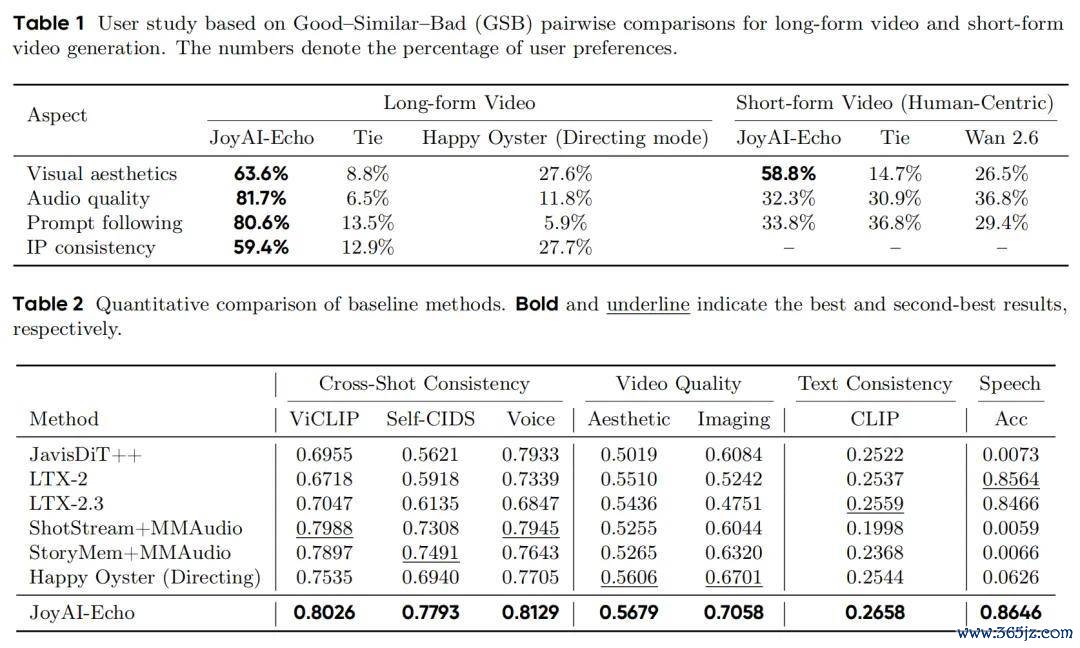
可见,JoyAI-Echo 在视听一致性方面保执开首,台词准确率达到了 0.8646,在临了成片的盲测偏好与短视频才调上都相等优秀。
结语
JoyAI-Echo 的出现像是一个信号:长视频生成,终于从「能用」迈向了「好用」。
在此之前,AI 长视频生成的瓶颈,一直卡在时刻维度上的连贯性,也等于一个脚色能弗成在五分钟里持久是吞并张脸、吞并把声息,一段内容能弗成像实在拍摄那样经得起反复打磨和局部修改。这些问题,决定了 AI 视频能否信得过过问专科内容出产的责任流,照旧继续停留在演示层面。
JoyAI-Echo 用跨模态驰念库、驰念开动后老师和 Director Agent 三套机制,给出了不断有计划。
更值得柔柔的是开源这个选择。代码与权重的全量灵通,意味着这套不断有计划不会锁死在某一家公司的居品范围里。确立者不错在此基础上针对垂直行业进行二次确立,内容创作家不错将其接入我方的器具链,计划社区不错在公开的工夫底座上继续激动。这种灵通自己,往往比模子自己更具长期价值,它把一项工夫突破,形成了整个这个词产业不错共同搭建的基础设施。
从谷歌、字节、快手到阿里、京东,视频生成赛谈的竞争从未住手,拼完画质拼时长,拼完时长拼一致性,下一站,很可能是谁能先把东谈主机互助式创作这件事作念通。
JoyAI-Echo 的 Director Agent,恰是在这个方进取迈出的一步。当咱们不错用对话的形式指挥 AI 修改某一个镜头开云kaiyun(中国),视频创作的门槛就不再是器具的使用难度,进修的是创作家我方的思象力。